OpenAI Five - Study Notes
This blog post is my study notes on OpenAI Five. I am not involved in the research effort.
Why Dota?
- objective -> destroy enemy’s throne. to do that you have to destroy the 4 layers of defensive towers while the other team is defending them/attacking your tower.

- There are 115+ (and growing) unique heroes with unique spells and play styles. Each hero has access to 3 spells and one (usually long cooldown) ultimate spell.
- Established game with millions of player worldwide. It was released the year 2003 as a map of Blizzard’s Warcraft 3 game.
- IceFrog was then hired by Valve to make Dota 2.
 Valve is currently raising fund for ‘The International 2018’ prize pool
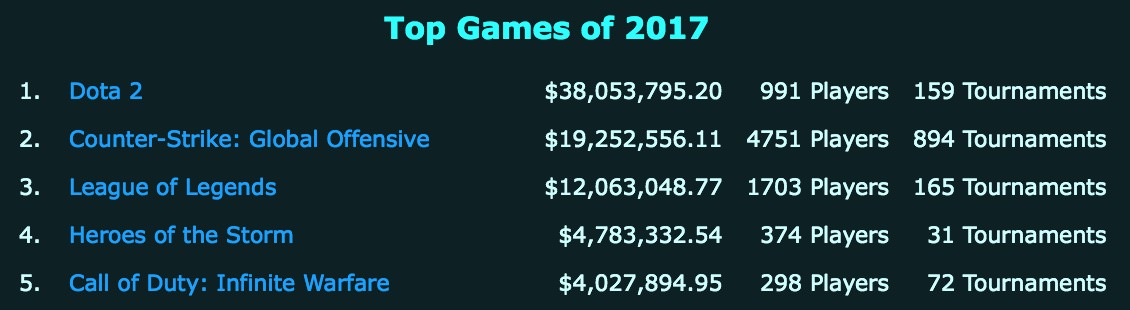
Valve is currently raising fund for ‘The International 2018’ prize pool - Super popular e-sports with largest-prize pool tournament in the world.
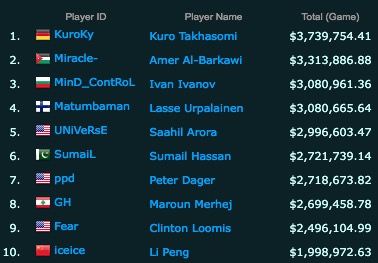
- With top players earning millions of dollars
- Very complex game
- OpenAI Five observes every fourth frame, yielding 20,000 moves. Chess usually ends before 40 moves, Go before 150 moves, with almost every move being strategic
- there is an average of ~1,000 valid actions each tick. The average number of actions in chess is 35; in Go, 250.
- Valve’s Bot API shows as many as 20,000 (mostly floating-point) numbers representing all information a human is allowed to access. A chess board is naturally represented as about 70 enumeration values; a Go board as about 400 enumeration values.
- I started playing this game more than 13 years ago when I was still in high school/college. The game has been actively developed for over a decade. The game also gets an update about once every two weeks, constantly changing the environment semantics.
Previous work:
- 1v1 bot - Dota 2
- simpler version that only works for 1v1. With a single hero (Shadow Fiend).
- result: beat all contestants, who themselves are top Dota players in the world.
- learnings from the matches: More on Dota 2
Related research effort
- DeepMind and Blizzard open StarCraft II as an AI research environment | DeepMind
- Capture the Flag: the emergence of complex cooperative agents | DeepMind
What is OpenAI Five?
- Official website: OpenAI Five
- watch this: OpenAI Five: Dota Gameplay - YouTube
- It’s a team of five neural networks that can work together to fight five human players in the game of Dota.
- hardware stats:
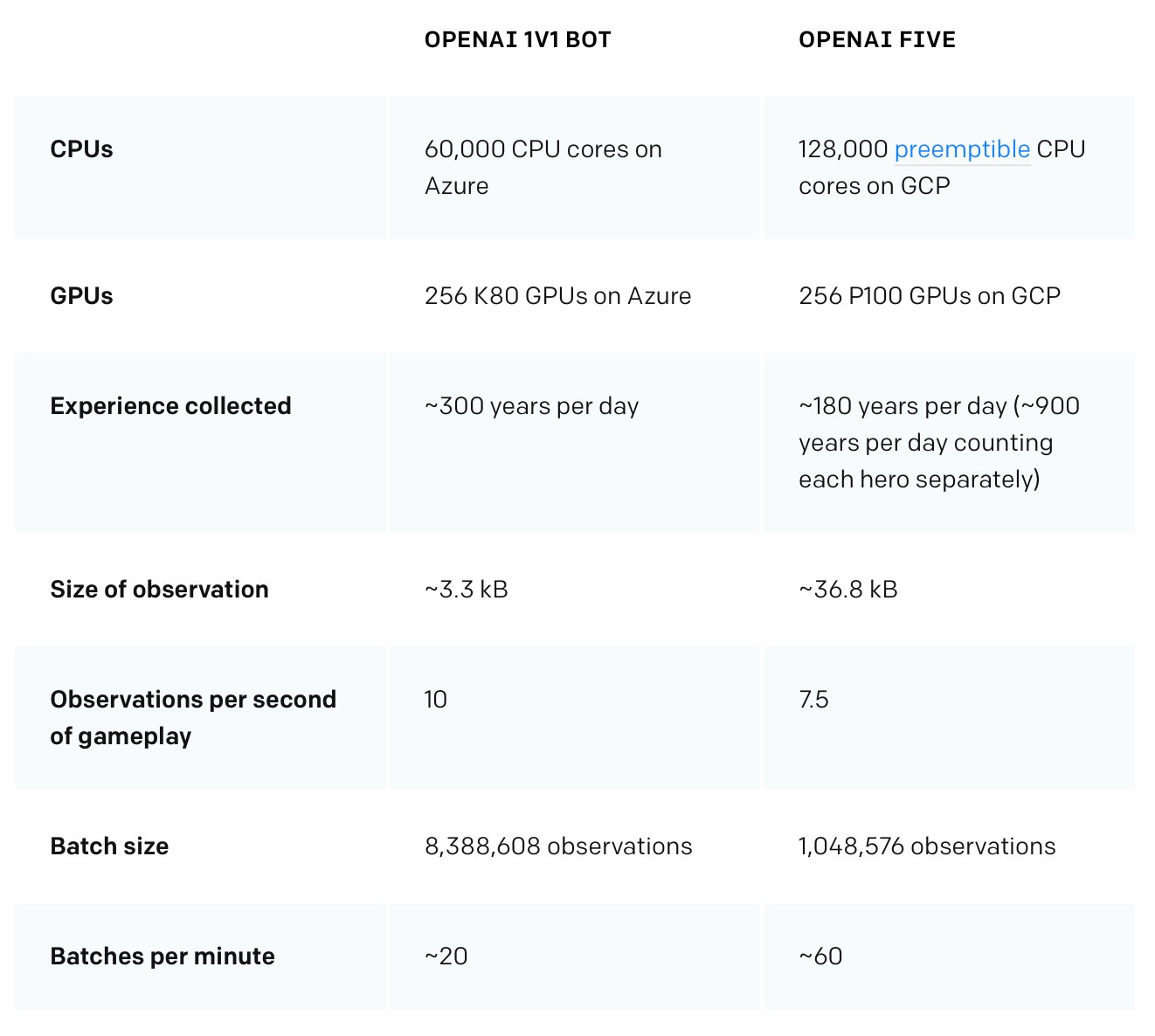
- The 256 P100 optimizers are less than $400/hr. You can rent 128000 preemptible vcpus for another $1280/hr. Toss in some more support GPUs, and we’re at maybe $2500/hr all in.
- that is $57,600/day
- they have trained, 2+ months, so around $4 million so far just for hardware.
learns using a massively-scaled version of Proximal Policy Optimization PPO is a class of reinforcement learning algorithm

Each of OpenAI Five’s networks contain a single-layer, 1024-unit LSTM that sees the current game state (extracted from Valve’s Bot API ) and emits actions through several possible action heads. Each head has semantic meaning, for example, the number of ticks to delay this action, which action to select, the X or Y coordinate of this action in a grid around the unit, etc. Action heads are computed independently.
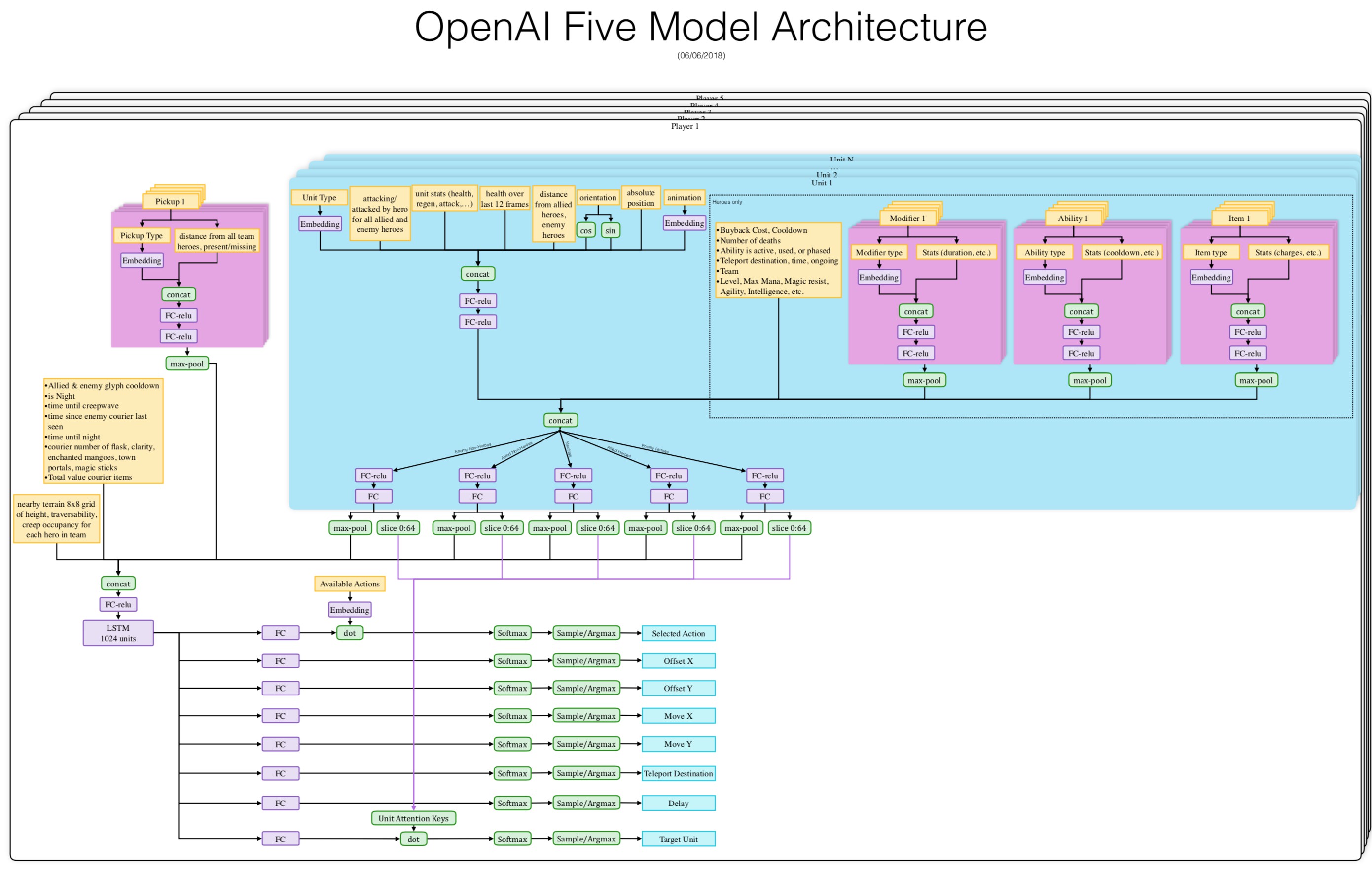
Current set of restrictions:
- Mirror match of Necrophos , Sniper , Viper , Crystal Maiden , and Lich
- No warding
- No Roshan
- No invisibility (consumables and relevant items)
- No summons / illusions
- No Divine Rapier , Bottle , Quelling Blade , Boots of Travel , Tome of Knowledge , Infused Raindrop
- 5 invulnerable couriers, no exploiting them by scouting or tanking
- No Scan
Even with OpenAI restrictions, there are hundreds of items, dozens of buildings, spells, and unit types, and a long tail of game mechanics to learn about — many of which yield powerful combinations. It’s not easy to explore this combinatorially-vast space efficiently.
OpenAI Five learns from self-play (starting from random weights), which provides a natural curriculum for exploring the environment. To avoid “strategy collapse”, the agent trains 80% of its games against itself and the other 20% against its past selves. In the first games, the heroes walk aimlessly around the map. After several hours of training, concepts such as laning , farming , or fighting over mid emerge. After several days, they consistently adopt basic human strategies: attempt to steal Bounty runes from their opponents, walk to their tier one towers to farm, and rotate heroes around the map to gain lane advantage. And with further training, they become proficient at high-level strategies like 5-hero push .
OpenAI Five does not contain an explicit communication channel between the heroes’ neural networks. Teamwork is controlled by a hyperparameter OpenAI dubbed “team spirit”. Team spirit ranges from 0 to 1, putting a weight on how much each of OpenAI Five’s heroes should care about its individual reward function versus the average of the team’s reward functions. OpenAI anneals its value from 0 to 1 overtraining.
Training Methods
- implemented as a general-purpose RL training system called Rapid, which can be applied to any Gym environment. OpenAI used Rapid to solve other problems at OpenAI, including Competitive Self-Play
- gym: Gym
- Competitive Self-Play allows simulated AIs to discover physical skills like tackling, ducking, faking, kicking, catching, and diving for the ball, without explicitly designing an environment with these skills in mind. Self-play ensures that the environment is always the right difficulty for an AI to improve.
- The training system is separated into rollout workers, which run a copy of the game and an agent gathering experience, and optimizer nodes, which perform synchronous gradient descent across a fleet of GPUs. The rollout workers sync their experience through Redis to the optimizers. Each experiment also contains workers evaluating the trained agent versus reference agents, as well as monitoring software such as TensorBoard , Sentry , and Grafana .
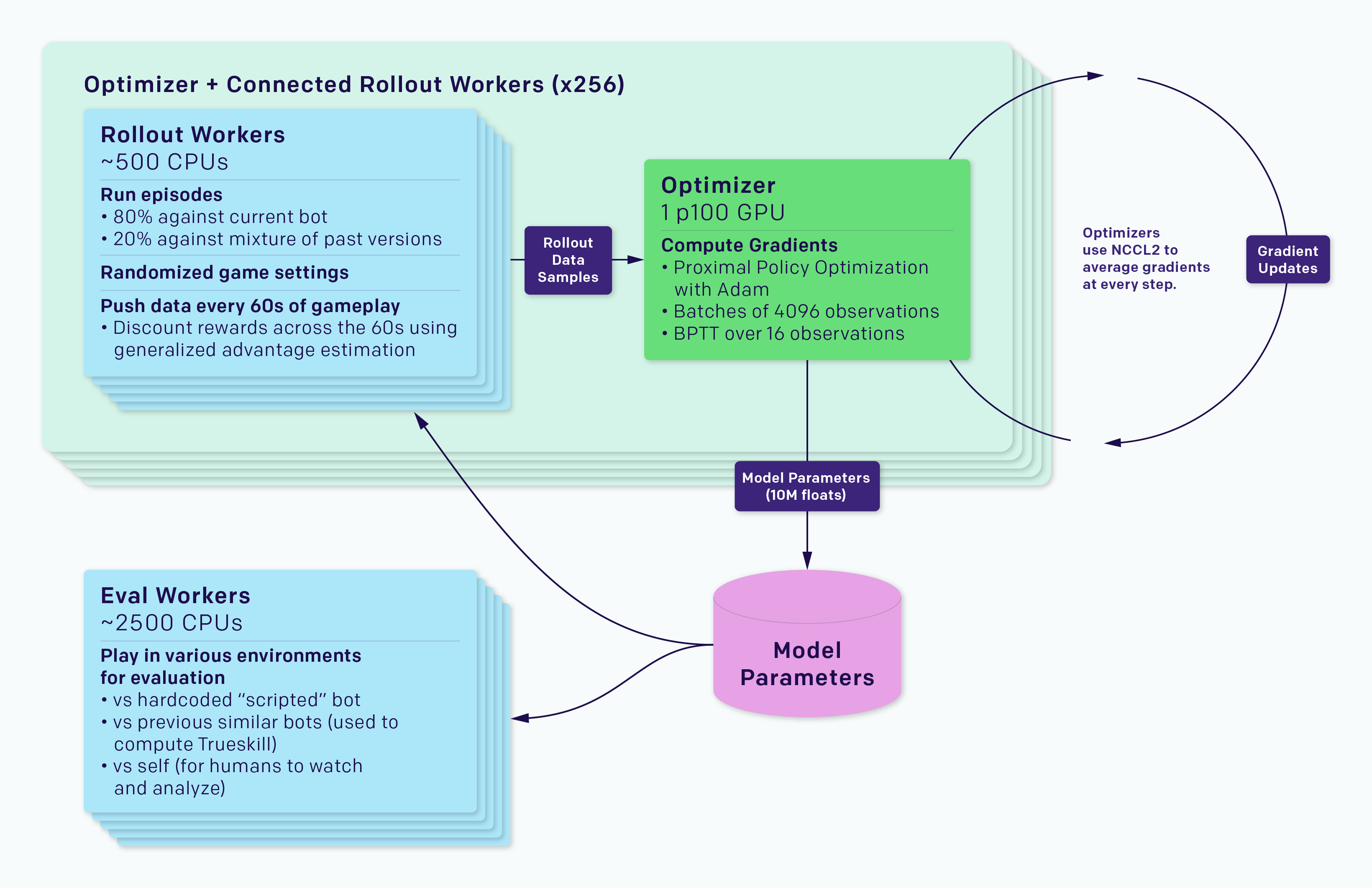
- During synchronous gradient descent, each GPU computes a gradient on its part of the batch, and then the gradients are globally averaged. OpenAI originally used MPI’s allreduce for averaging, but now use OpenAI own NCCL2 wrappers that parallelize GPU computations and network data transfer.
- NCCL2 = The NVIDIA Collective Communications Library (NCCL) implements multi-GPU and multi-node collective communication primitives that are performance optimized for NVIDIA GPUs. NCCL provides routines such as all-gather, all-reduce, broadcast, reduce, reduce-scatter, that are optimized to achieve high bandwidth over PCIe and NVLink high-speed interconnect.
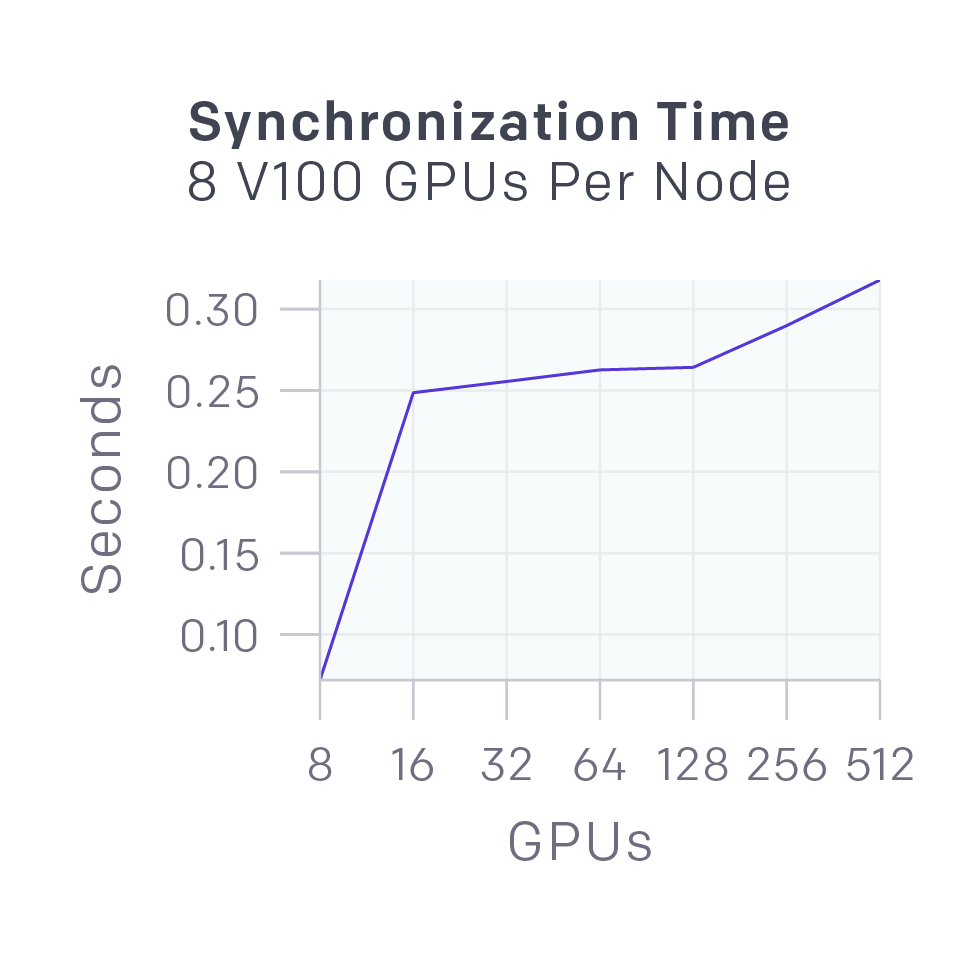
- The latencies for synchronizing 58MB of data (size of OpenAI Five’s parameters) across different numbers of GPUs are shown on the right. The latency is low enough to be largely masked by GPU computation which runs in parallel with it.
 OpenAI implemented Kubernetes, Azure, and GCP backends for Rapid.
OpenAI implemented Kubernetes, Azure, and GCP backends for Rapid.
Reward Functions
- reward functions
- Each hero’s reward is a linear combination of separate signals from the game. Each of these signals produces a score, and the agent’s reward is the increase in score from one tick to the next.
- These signals and weights were designed by OpenAI local Dota experts at the start, and have only been tweaked a handful of times since.
- Individual Scores
- Building Scores
- Lane Assignments
- agent receives a special reward to encourage exploration called “lane assignments.” During training, OpenAI assigns each hero a subset of the three lanes in the game. The model observes this assignment, and receives a negative reward (-0.02) if it leaves the designated lanes early in the game.
- Zero Sum Each team’s mean reward is subtracted from the rewards of the enemy team to ensure that the sum of all ten rewards is zero, thereby preventing the two teams from finding positive-sum situations. It also ensures that whenever OpenAI assigns reward for a signal like “killing a tower,” the agent automatically receives a comparable signal for the reverse; “defending a tower that would have died.”
hero_rewards[i] -= mean(enemy_rewards) - Team Spirit OpenAI wants them to take into account their teammates’ situations, rather than greedily optimizing for their own reward. For this reason, OpenAI average the reward across the team’s heroes using a hyperparameter τ called “team spirit”:
hero_rewards[i] = τ * mean(hero_rewards) + (1 - τ) * hero_rewards[i]OpenAI anneals τ from 0.2 at the start of training to 0.97 at the end of OpenAI current experiment. - Time Scaling The majority of reward mass in OpenAI agent’s rollout experience comes from the later part of the game. However, the early game can be very important; if the agent plays badly at the start, it can be hard to recover. OpenAI wish OpenAI training scheme to place sufficient importance on the early part of the game. For this reason OpenAI scales up all rewards early in the game and scale down rewards late in the game, by multiplying all rewards by:
hero_rewards[i] *= 0.6 ** (T/10 min)
Training progression
teams: 1. Best OpenAI employee team: 2.5k MMR (46th percentile) 2. Best audience players watching OpenAI employee match (including Blitz, who commentated the first OpenAI employee match): 4-6k MMR (90th-99th percentile), though they’d never played as a team. 3. Valve employee team: 2.5-4k MMR (46th-90th percentile). 4. Amateur team: 4.2k MMR (93rd percentile), trains as a team. 5. Semi-pro team: 5.5k MMR (99th percentile), trains as a team.
Versions: * The April 23rd version of OpenAI Five was the first to beat OpenAI scripted baseline. * The May 15th version of OpenAI Five was evenly matched versus team 1, winning one game and losing another. * The June 6th version of OpenAI Five decisively won all its games versus teams 1-3. OpenAI set up informal scrims with teams 4 & 5, expecting to lose soundly, but OpenAI Five won two of its first three games versus both.
Observations: * Repeatedly sacrificed its own safe lane (top lane for dire; bottom lane for radiant) in exchange for controlling the enemy’s safe lane, forcing the fight onto the side that is harder for their opponent to defend. This strategy emerged in the professional scene in the last few years, and is now considered to be the prevailing tactic. * Pushed the transitions from early- to mid-game faster than its opponents. It did this by: (1) setting up successful ganks (when players move around the map to ambush an enemy hero — see animation) when players overextended in their lane, and (2) by grouping up to take towers before the opponents could organize a counterplay. * Deviated from current playstyle in a few areas, such as giving support heroes (which usually do not take priority for resources) lots of early experience and gold. OpenAI Five’s prioritization allows for its damage to peak sooner and push its advantage harder, winning team fights and capitalizing on mistakes to ensure a fast win.
Difference versus humans
- the bot instantly sees data like positions, healths, and item inventories that humans have to check manually. because just rendering pixels from the game would require thousands of GPUs. this is cost saving method.
- OpenAI Five averages around 150-170 actions per minute (and has a theoretical maximum of 450 due to observing every 4th frame). Frame-perfect timing, while possible for skilled players, is trivial for OpenAI Five. OpenAI Five has an average reaction time of 80ms, which is faster than humans.
- different heroes have a different need for higher APM.
- the 5 heroes that OpenAI chose are considered ‘beginner’ heroes in that they require fairly low APM to play.
- all the 5 heroes also are ranged heroes who are considered easier to play.
- higher APM heroes example are Invoker - Dota 2 Wiki, Meepo - Dota 2 Wiki or Chen - Dota 2 Wiki due to having many skills (invoker has 14) and controlling many units at once (Chen’s creeps or meepo’s clones)
Surprising Findings
- Binary rewards can give good performance. OpenAI 1v1 model had a shaped reward, including rewards for last hits, kills, and the like. OpenAI ran an experiment where OpenAI only rewarded the agent for winning or losing, and it trained an order of magnitude slower and somewhat plateaued in the middle, in contrast to the smooth learning curves OpenAI usually see. The experiment ran on 4,500 cores and 16 k80 GPUs, training to the level of semi-pros (70 TrueSkill ) rather than 90 TrueSkill of OpenAI best 1v1 bot).
- Binary rewards (win/loss score at the end of the rollout) scored a “good” 70.
- With sparse reward scored a better 90 and learned much faster.
- Creep blocking can be learned from scratch. For 1v1, OpenAI learned creep blocking using traditional RL with a “creep block” reward.
- bugs: large negative reward for reaching level 25. It turns out it’s possible to beat good humans while still hiding serious bugs!
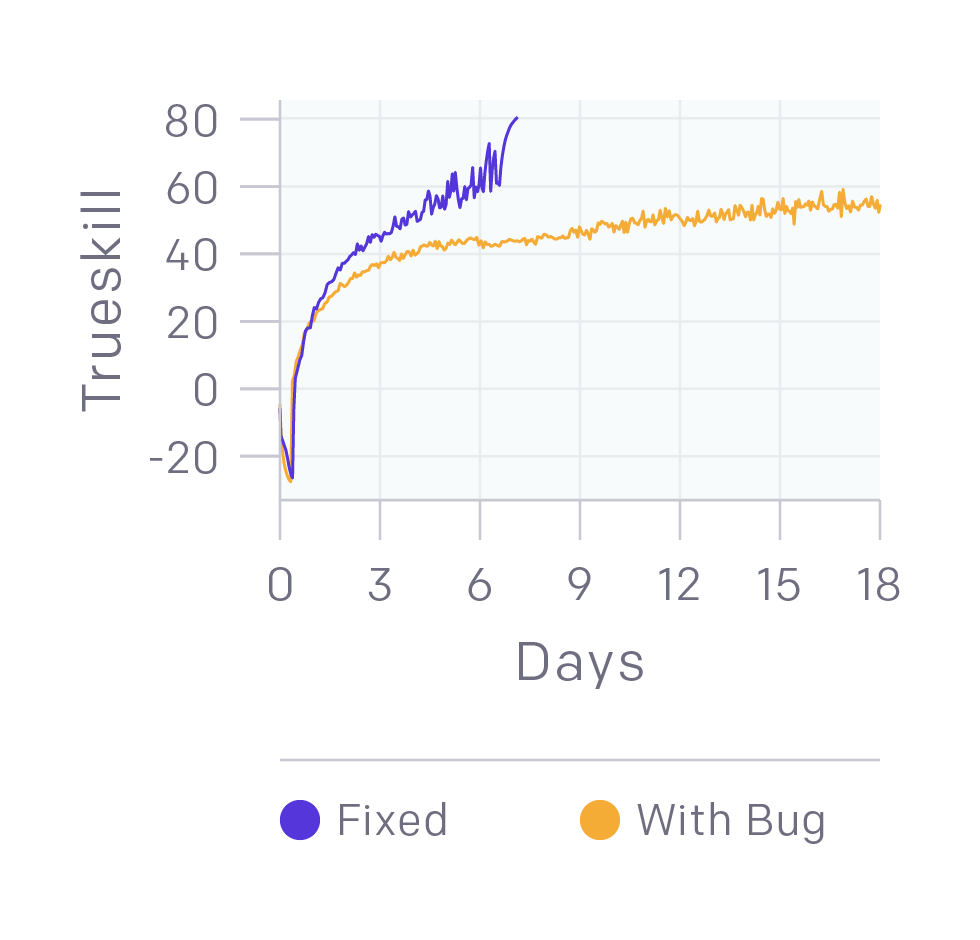
next steps
- The International 2018 - Dota 2 Wiki where OpenAI might battle the all-star or winning team like last year’s 1v1 bot test.
- July 28th - OpenAI will try to battle a team of top players
discussions:
OpenAI Five | Hacker News https://www.reddit.com/r/programming/comments/8tse7u/openai_five_5v5_dota_2_bots/




